Research
- JF:
- Let's discuss your research. Just from your homepage I got that your research involves "using computational modeling to explore the nature of normal and impaired cognitive processing in higher-level vision, attention, and language." So, can we talk a little about that? What's come up in your exploration of these areas?
- DP:
-
Ok. One of the challenges in the kind of work that I do and the kind of
problems that I am interested in is that you're trying to span between a
biological, neurophysiological processing and very high-level
cognitive processing. One way to think about the kind of work that I do
is that I am trying to find the kinds of computational principles and
systems that can bridge the gap between the two. And that often involves
making compromises on both sides. So, the modeling work that I do is
generally not cast at a very neurophysiological level. It tries to capture
the general properties of information processing of large groups of neurons.
That's partly because the focus of the work is trying to characterize
behavior, trying to capture systems that can actually exhibit behavior we
can compare directly with human subjects' behavior, both normal subjects or
those that have suffered brain damage. And that is a challenge, to
try to build models that can perform tasks as complex as those of people
and yet still try to reach down toward the neurophysiology and make contact
with, at least at a general level, the kinds of principles and
the constraints that operate on neural computation.
It's a challenge on the other side, the cognitive side, because our understanding of how information can be represented in large groups of neurons, how they can interact, how those kinds of parallel systems can actually perform cognitive processing, and the methodologies we have to implement those kinds of processes are still very limited. In some sense, it's a very restricted kind of formalism. It's not like general programming, where you can sit down and write any code that you want. By and large, the systems are developed through training, through learning in an environment where you present them with examples of the task that they're trying to perform and a fairly general learning algorithm or procedure is used to adjust the connection weights, so that performance gradually gets better and better. But, as an experimenter, that's a fairly indirect way of developing systems. And so you have to live with the limitations and the constraints of what kinds of things are learned easily, what kinds of things aren't learned easily, what things are impossible; the way information is represented influences what it learns. In some sense, you tie a hand behind your back in terms of implementing the process.
Now, the payoff is that, if the constraints and formalism capture something important about the neural mechanism and the constraints it operates under, then you are actually further along in the process, because you should find that the kinds of things the system finds more easy or difficult to do correspond to the kinds of things people find more easy or more difficult to do. Or the kinds of things that tend to be robust under damage are also the kinds of things that tend to survive under brain damage. So, the challenge of the approach is to work within the framework, within the constraints, and flesh out the way that those constraints lead to the kinds of patterns of performance you see, while hopefully not doing anything terribly implausible because, again, the goal is also to try to move the work closer to the neurobiology.

- JF:
- Can you give us a specific example of this approach? What has it been applied to?
- DP:
-
Sure. In the deep dyslexia modeling work with Tim Shallice, following on
what he had done with Geoff Hinton, we tried to show how some fairly general
principles of neural computation - using distributed patterns of
activity to represent words and their meanings, having units interact to
represent word meanings as stable patterns of activity over some large
number of units, the so-called forming attractors for word meanings - how those
kinds of principles could provide an explanation for a type of neurological
patient that exhibits a fairly strange kind of combination of symptoms
known as deep dyslexia.
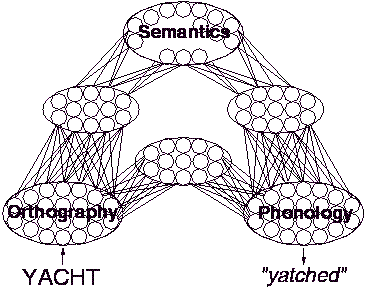
Typically there is fairly extensive left hemisphere damage and often they have other language problems, but in their reading, pronouncing single words, they produce a particular sort of signature symptom, which is that they produce semantic errors. They'll misread a word like RIVER; they may say OCEAN. Now, it's one thing to have semantic confusion in, say, picture naming, but in word reading RIVER doesn't look anything like the word OCEAN. So, it's clear that they're getting something about the meaning of the input because they're getting a response that is related to the input, but there is also obviously something is going wrong. It's also not as if they may have recognized the word RIVER as some sort of discrete event, because, then, why couldn't they just say the word RIVER?
So, the insight that came out of the Hinton and Shallice work was that you could interpret these kinds of errors as cases where, because of damage, the pattern of activity that the network generated - the interpretation of the input - would get captured by an attractor for a related meaning. The interaction of units, instead of settling one way, would settle the other way. And that settling into some other pattern would tend to be a related word, because related words like RIVER and OCEAN tend to have similar patterns that represent them. They demonstrated the occurrence of these kinds of errors under damage.
- JF:
- I'm curious. When you damage these models, are you removing connections or removing units or adding some perturbation to the output?
- DP:
-
All of those have actually been tried in different models, as well as a
number of others. Their original work and most of my work has
focused on looking at the permanent removal of units and connections.
Partly to try to stay as close to the equivalent brain damage as
possible. Most of these patients are stroke patients where there is some
brain tissue that's died.
- JF:
- How would you relate the removal of elements from your network to a stroke patient?
- DP:
-
Well, the relationship is indirect because I don't think of single
units as corresponding directly to single neurons. The way I think
about it is that the groups of units in a network may each represent a
particular type of information or may represent areas that accomplish the
transformation between different types of information, like the written form
of a word and its meaning. The hypothesis is that the way in which groups
of units represent and process information captures some
important properties of the way groups of neurons, small cortical
areas, represent and process information, so that a lesion in a model, which
amounts, generally, to selecting at random some proportion of the units say
in a layer and eliminating them, is an approximation to a stroke, that
might be the result of the death of some proportion of the neurons or some
set of the neurons in a cortical area. You can essentially apply the
same procedure to connections; it can be a proportion of connections between
two groups of units.
There's a lot of other types of damage and other distinctions that one can introduce. So, for instance, one might distinguish focal lesions in a model, removing connections only from a particular part, from more diffuse lesions, where you might randomly remove connections throughout the entire network. Steve Small at Pitt Neurology has looked at some of those kinds of distinctions and, in fact, different models of damage can have different effects. We've also looked at adding noise to connections as an approximation to removing connections from a much larger system. One of the challenges is obviously that the networks we build are much smaller than the actual cortical systems. One way of approximating or compensating is to approximate real structural damages in the real cortical system with distortions, like adding noise to weights from connections in the model. By and large, those types of manipulations tend to produce similar effects. The noise will tend to produce somewhat smoother results because it can be controlled a little more carefully, but we certainly found that - and these were supposed to be focal lesions - the behavior of the damaged network is much more dependent on the kind of task it's performing, the knowledge it developed in the first place, than on the particular way you happen to damage it.
So we try... Obviously this is an area where we are developing the techniques further, but, to the extent that we can, we try to have the manipulation in the model that corresponds to brain damage be as analogous as possible. And that's obviously one area in which collaboration with neuropsychologists and neurologists is critical because they can tell us: "Wait, in fact, it turns out this type of patients have a particular type of brain damage and it is better approximated with this kind of manipulation in the model." To the extent that those distinctions lead to better accounts of the behavior, then it is very important to introduce those kinds of distinctions into the model.
- JF:
- So your lesioning of these networks resulted in what kind of behavior?
- DP:
-
Right, so coming back to dyslexic patients, the occurrence of these semantic
errors followed in a somewhat straightforward manner from the existence of these
attractors and the fact that the attractor for a related word meaning might
capture the initial pattern from a word. What's striking about the patients
is not just that they produce semantic errors, but that they exhibit a whole host
of other symptoms. They also produce visual errors, so they might say RIVET
to RIVER or a similar word. They can produce interesting
mixtures of visual and semantic relatedness in their errors.
A particularly strange example is cases of what are called 'visual then semantic' errors, one following the other. So, an example would be reading the word SYMPATHY as ORCHESTRA, presumably via first going from SYMPATHY to SYMPHONY as a visual error and then SYMPHONY to ORCHESTRA as a semantic error. In accounting for those combinations of errors, visual errors/semantic errors/mixed errors/visual and semantic errors, researchers have, in the past, had to propose that there were two separate lesions. There was a lesion that caused the visual error and a lesion that caused the semantic error and you could then get one or the other or both.
There are also other factors influencing the degree to which patients will make errors on words. So, they're better at reading nouns than they are at verbs. They're better at verbs than, say, adjectives and adverbs. And function words are very poorly read. And, in fact, for non-words - pronounceable strings that don't have meaning - these patients are essentially unable to read those. Now, you and I and many other types of patients can read, you know, like M-A-V-E, you can say MAVE, no problem. These patients will say: "don't know, have no idea." Or they might say MAKE, if they have to, they might come up with a response that's another word.
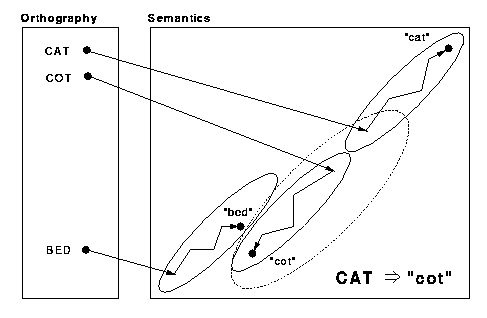
They're also influenced by the nature of the meaning of the word. So they are better at reading concrete or highly imageable words, like TABLE, than they would abstract words, like TRUTH. It's not quite clear what the underlying variable is. Anyway, there is a whole host of other symptoms that arise in these patients that make semantic errors. One of the things that's come out of the computational work is that it's not necessary to assume that they have all these different separate lesions that produce all the different symptoms, but that that combination of symptoms arises naturally in systems that have learned to map between, say, the written form of words and their meanings and from them onto their pronunciations. That is, it's inherent in the nature of that kind of computational system that it will produce a mixture of visual errors and semantic errors, and if you make assumptions about the relative richness of the meanings of different words, they also give rise to these effects of concreteness and imageability, part of speech effects, and so on.So the computational investigation, in part, showed that the principles can provide insight into what is otherwise a strange combinations of symptoms. They are understandable in a particular kind of computational framework. So, I think that that's one aspect, one direction, of the kind of work that I do.
There's another side, which we went to great pains to try to accomplish in the deep dyslexia work, which is to demonstrate the generality of the effects. I think a limitation of a lot of modeling work is that often a single simulation is put forth as the answer to some phenomenon, whereas we felt that it's premature really to do that. In fact, modeling is really much more of an exploration, where you are trying to understand the implications of a set of principles.
So, in addition to trying to extend the approach to account for this range of symptoms, we also carried out a whole range of simulations trying to determine what aspects of the networks led to their performance. Did it matter, exactly, what the architecture was, how the units were connected? Did it matter exactly what training algorithm was used? Did it matter how the inputs and outputs were represented? Did it matter exactly how the meaning of words were defined? And so we carried out, not exactly a fully orthogonally crossed design, that would be a huge amount of simulating (we actually did a lot)... But a number of insights came out of that, other than just to verify the basic approach used.
One is that what we think is important isn't always important. One might imagine that the architecture, the nature in which groups of units are connected, is important for understanding the behavior of networks. That turned out to be less true than, at least I, originally thought. The networks have to have the ability to form attractors; units have to be able to interact bi-directionally or collectively so as to settle into stable states. But the specific connectivity that allows them to do that isn't so critical. It doesn't so much matter whether you use separate units that allow a group of units to interact and form attractors or whether the same units that are mapping between orthography and semantics, or semantics and phonology, those same units are used to interact to form attractors. The same basic pattern of performance arises.
I think that both of those sides of the work are important. Both extending the empirical coverage of the approach as well as demonstrating the generality - that it wasn't some idiosyncratic thing we did that produced that combination of effects.
- JF:
- Did you get any predictions from your model?
- DP:
-
There are a couple of things, empirical effects we did not know
about in developing the model that have turned out to be true of the model.
Now, I don't tend to think of them as predictions, in the sense that we
didn't sit down and see if the model did this before gathering the data,
because, in some sense, everything the model does is a prediction. Now, you
wouldn't want to take everything that seriously. Often in modeling work
it's important to focus your efforts on what are the theoretically
interesting questions, not just run every word through the network and see
what it does.
So, one of the issues that we did explore after having developed the network had to do with the relationship between the concreteness effect (the fact that concrete words are read better than abstract words) and patients with visual impairments that are in even more peripheral parts of the system - patients with what is called 'neglect dyslexia'. An aspect of unilateral neglect patients, who are patients with visual attentional problems, is that they tend to ignore one half of a stimulus (usually the left, because it usually occurs following right parietal damage, but it can occur on the right side following left or bilateral parietal damage).
The idea is that these patients either fail to attend to stimuli on that side or they fail to attend to half a stimulus on one side. This can often manifest in reading, where they will be presented with a word like TABLE and, because they might not see LE on the right hand side (with right neglect, they may only sort of see the TAB...), they might read that as TABLET or.... (It's not actually a very good example because there are not many words that end on that side.) What we learned after having developed the model was that these patients, at least those that have been tested, also show a concreteness effect, so that they are more likely to produce these neglect errors to abstract words. So, TRUTH to TRUCK, that would be a right neglect error. There are patients studied by David Howard and Wendy Best who are much more likely to make these neglect errors to abstract words than concrete words.
So, we tested our model; we can produce these kinds of errors. We tested our model by degrading the visual input roughly in an analogous way to an attentional impairment and showed that, in fact, the model tends to produce more of these neglect errors to abstract words. They're neglect errors in the sense that they tend to be more accurate on the left hand side for right neglect errors. And the network didn't produce the semantic errors. Because these patients, these neglect patients, don't produce semantic errors, they just produce these visual effects.
So, that's a case where the network, the simulation, could provide an account of a set of patients, of the behavior of a set of patients, that didn't enter into the design of the network. Now, it's true that they told us about this result before we went and tested the model, so I don't know if that counts as a prediction, but it's certainly a case in which the model has provided an account for a range of data beyond what it was originally designed for.
 .
Back to the index.
.
Back to the index.

| Got a suggestion? Send us a note! | Have and idea to share? Post it to the CNBC Newsgroup! |
 |